Conversational Question Answering
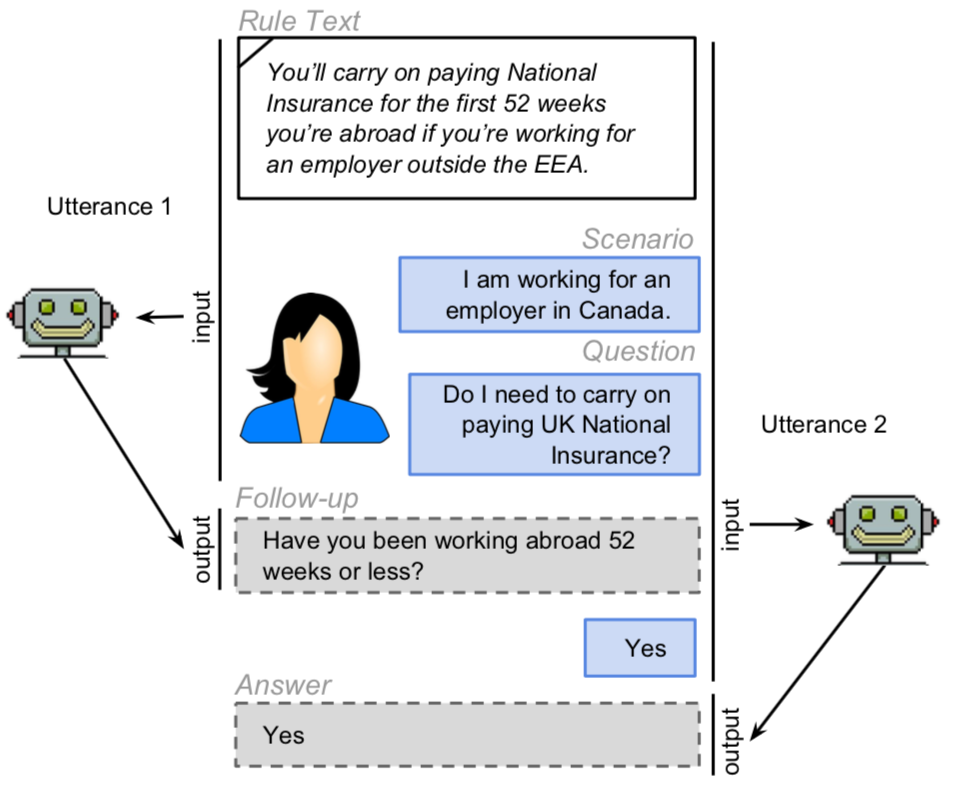
Most work in machine reading focuses on question answering problems where the answer is directly expressed in the text to read. However, many real-world question answering problems require the reading of text not because it contains the literal answer, but because it contains a recipe to derive an answer together with the reader's background knowledge. We formalise this task and develop a crowd-sourcing strategy to collect 32k task instances.